Il KNOT Data Model - Panoramica
Una linea guida per la descrizione dell'attività scientifica e degli scholarly digital objects come patrimonio culturale, utilizzando un vocabolario comune e facilitando la diffusione di buone pratiche.
Il processo di modellazione nelle Digital Humanities è fondamentale per passare dalla teoria alla pratica [1], trasformando il pensiero critico e l'interpretazione in un oggetto potenzialmente pratico come un modello di dati. Inoltre, la modellazione, sia nel campo dei beni culturali che in quello delle Digital Humanities, non riguarda solo la rappresentazione della fonte, ma anche il processo stesso, in parte perché questo processo implica la rappresentazione e la cattura di alcune delle soggettività e delle peculiarità intrinseche delle creazioni e delle attività umane per esprimere principi che sono ancorati a un contesto specifico piuttosto che a una legge generale [1].
Il KNOT Data Model (KNOT-DM) è stato sviluppato per catturare alcune delle peculiarità della nostra argomentazione sugli scholarly digital objects come esempi unici e interessanti del patrimonio culturale digitale (PCD) delgli Atenei italiani (si veda la pagina Pilot per saperne di più), e fungere da linea guida per la descrizione degli scholarly digital objects e la loro attività come PCD utilizzando un vocabolario comune e facilitando la diffusione di buone pratiche.
La metodologia SAMOD è stata utilizzata come punto di riferimento nello sviluppo del KNOT-DM per creare un flusso di lavoro iterativo: abbiamo innanzitutto utilizzato i risultati del nostro censimento (dei progetti e degli oggetti prodotti di scienze umanistiche in Italia) per creare un insieme iniziale di requisiti, come la capacità di descrivere sia scholarly digital objects che l'attività che li ha creati, i diversi tipi di oggetti e di accesso, e la loro dimensione di patrimonio culturale; abbiamo quindi valutato vari standard, modelli, ontologie e vocabolari esistenti per la loro interoperabilità, lo sviluppo e il supporto in corso, e l'uso in applicazioni reali; in seguito abbiamo ristretto la nostra scelta di standard e ontologie esistenti e li abbiamo valutati rispetto a una prima serie di domande di competenza (chi, cosa, dove, quando, come) modellando un piccolo sottoinsieme di dati del censimento (12 voci); in seguito sono stati apportati ulteriori perfezionamenti agli elementi degli standard che il modello doveva utilizzare e al modo in cui dovevano essere collegati e usati; le intuizioni di questa fase hanno portato anche alla creazione dei KNOT Controlled Vocabularies; infine, è stata creata la prima versione dell'ontologia e della documentazione del data model, attingendo alle intuizioni acquisite in ogni fase precedente.
L'uso di standard riconosciuti e complementari a livello internazionale deriva da una decisione iniziale di design secondo la quale KNOT-DM dovrebbe essere incentrato sulla riutilizzabilità piuttosto che sulla creazione di nuovi componenti ontologici, al fine di consentire la flessibilità e garantire la compatibilità finale con l'infrastruttura della Digital Library.
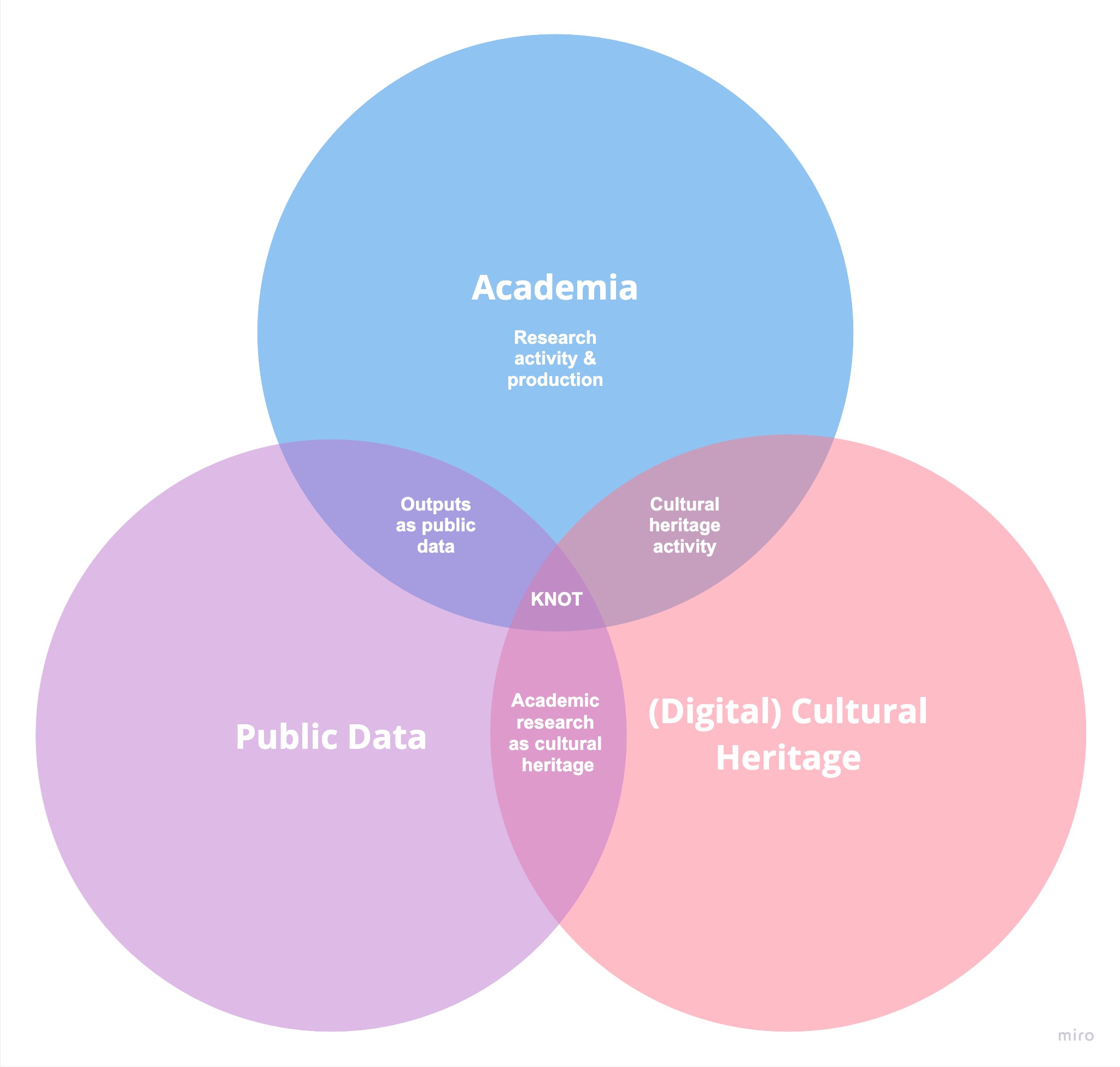
Uno dei principali aspetti emersi durante il processo di sviluppo è stata la comprensione che il dominio che ci interessava modellare si trovava all'intersezione di tre domini esistenti che rappresentano aspetti specifici della nostra argomentazione a favore degli scholarly digital objects come esempi del patrimonio culturale digitale degli Atenei italiani: il mondo accademico, dati pubblici e patrimonio culturale digitale. Questo ha portato a un modello progettato con tre segmenti interconnessi, che riflettono questa intersezione, in grado di rappresentare entità, attività, agenti, temi, relazioni e informazioni spazio-temporali.
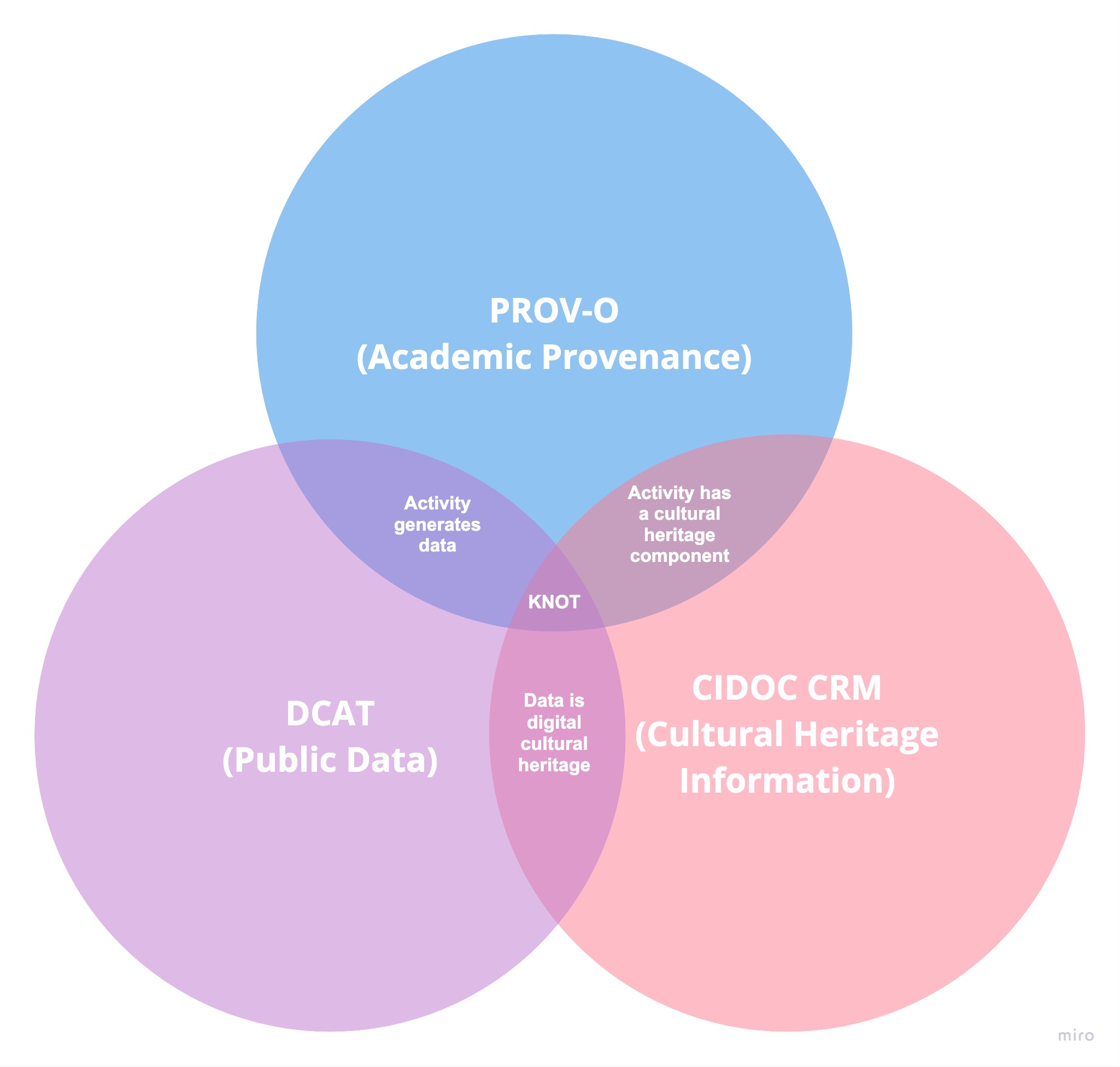
I Venn diagram riportati nella figura 1 riassumono l'intersezione di domini su cui si basa KNOT-DM e gli standard equivalenti che utilizza. Si vede la sezione Struttura per maggiori dettagli su come il modello di dati integra ogni standard.
L'obiettivo di KNOT-DM è quello di facilitare la descrizione dell'attività di ricerca e i scholarly digital objects come esempi di PCD (a partire dai dati prodotti dal progetto) e di favorire l'interconnessione con i sistemi esistenti che già documentano questa attività e questi oggetti, come i repository (sia istituzionali che pubblici) e i siti web dedicati, per evitare la duplicazione di dati e informazioni esistenti. Una prima area di interesse in questo senso è l'esplorazione di come KNOT possa integrarsi con il sistema di gestione della ricerca IRIS offerto agli Atenei dal CINECA.
I metadati creati con KNOT-DM costituiscono la base del knowledge graph usato nel catalogo KNOT.
Il KNOT-DM è concepito per essere flessibile e riutilizzabile. È liberamente disponibile per le università e altre parti interessate, che possono utilizzarlo per modellare i propri dati per uso indipendente o per consentirne l'inclusione nel progetto pilota KNOT.
KNOT-DM consente di registrare le seguenti informazioni:
- Attività del progetto di ricerca - chi, cosa, dove, quando e come.
- Output dei progetti di ricerca - gli scholarly digital objects creati dalle attività dei progetti di ricerca. (Il data model è sufficientemente flessibile da consentire la descrizione di vari oggetti possibili, come software, siti web, documentazione, servizi web e raccolte di dati.)
- Input del progetto di ricerca - le entità che alimentano un progetto di ricerca come oggetti fisici, persone, luoghi e temi.
- Agenti - coinvolto in progetti e creazione di oggetti come contributor o publisher, dall'individuo all'organizzazione attraverso le unità organizzative (come i dipartimenti o i laboratori) e le loro sedi.
- Relazioni - tra attività, agenti, entità, luoghi, e concetti, come l'influenza di concetti esterni o il riutilizzo di scholarly digital objects tra progetti.
- Informazioni spaziali e temporali - dei progetti ma anche quelle registrate negli scholarly digital objects, come ad esempio i luoghi citati in un testo o il periodo di tempo coperto dai dati.
- Concetti - come il tipo di oggetto, le tecnologie utilizzate, le attività di ricerca, le specifiche tecniche, le discipline accademiche coinvolte e gli argomenti di ricerca. Questi concetti sono descritti utilizzando una selezione di vocabolari controllati e controlli di autorità.
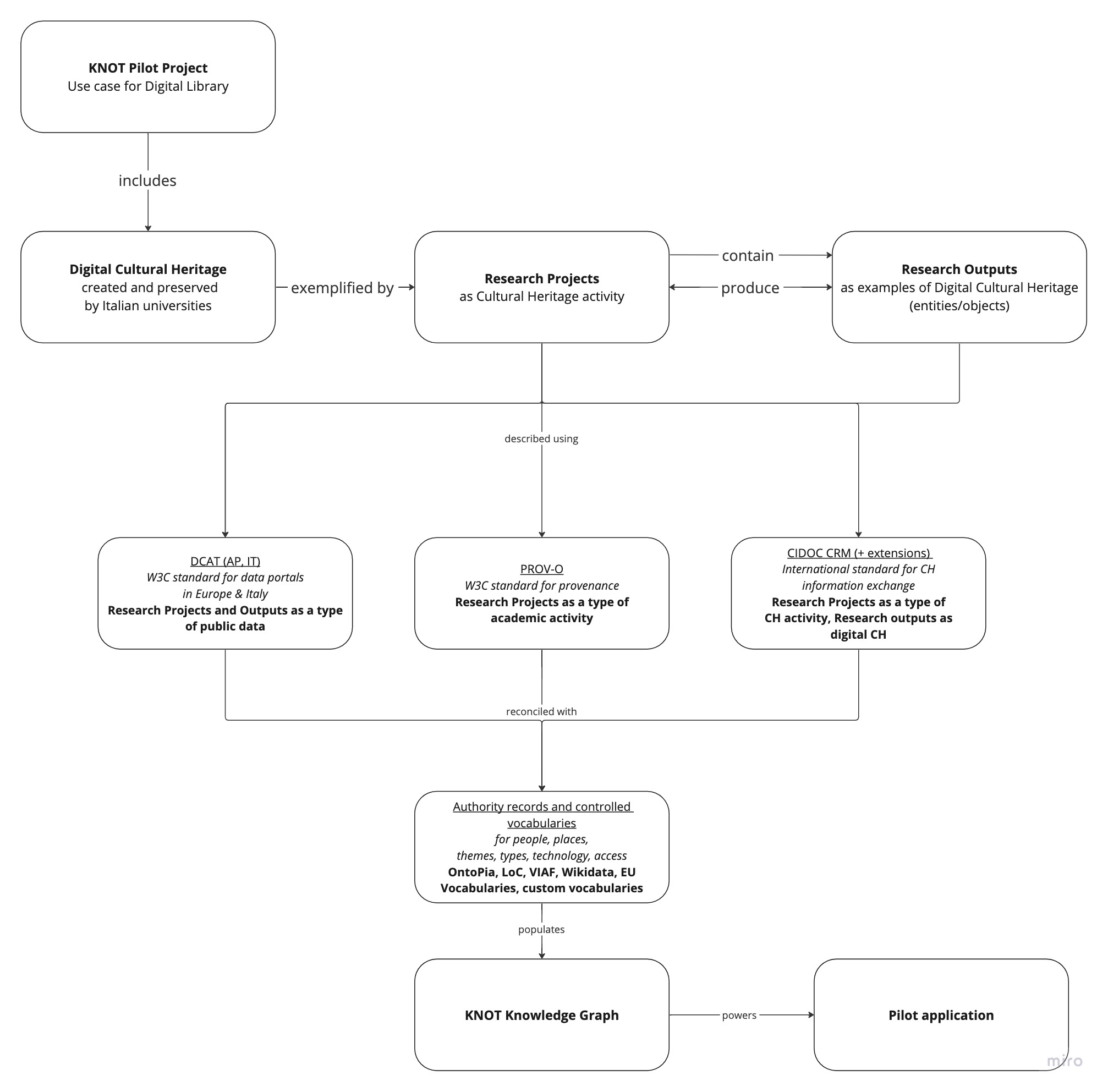
La figura 2 riassume il flusso di lavoro del KNOT-DM, in linea con gli obiettivi del primo anno del progetto.
References
[1] Tomasi, Francesca. 2018. “Modelling in the Digital Humanities: Conceptual Data Models and Knowledge Organization in the Cultural Heritage Domain.” https://doi.org/10.12759/HSR.SUPPL.31.2018.170-179.[2] Ciula, Arianna, Øyvind Eide, Cristina Marras, and Patrick Sahle. 2018. “Models and Modelling between Digital and Humanities. Remarks from a Multidisciplinary Perspective.” GESIS - Leibniz Institute for the Social Sciences. https://doi.org/10.12759/HSR.43.2018.4.343-361.
Struttura
Scopri di più sui diversi segmenti che compongono il KNOT-DM.
Moduli
Scopri di più su come utilizzare i diversi moduli di KNOT-DM.
L'Ontologia
Scopri di più sull'ontologia KNOT che esprime il Data Model in RDF.
Vocabolari Controllati
Scopri di più sui vocabolari controllati utilizzati in KNOT-DM, compresi quelli creati appositamente per il progetto.