Il KNOT Data Model - Vocabolari Controllati
KNOT-DM utilizza un insieme specifico di authority record e vocabolari controllati per descrizioni tematiche di concetti chiave e riconciliazione.
KNOT-DM fa uso di authority record e di vocabolari controllati esterni ricavati dai requisiti di DCAT e del progetto. Questi sono elencati di seguito. Inoltre, sono stati creati due vocabolari controllati appositamente per il progetto (si vede sotto). Si veda la sezione Relazioni della pagina Moduli per i dettagli su come i concetti di questi vocabolari e autorità possono essere collegati alle classi che rappresentano attività, entità, agenti e luoghi.
- Il vocabolario controllato Licenze di AgID è utilizzato per specificare le licenze.
- Il vocabolario controllato delle Aree CUN, dei Macrosettori, dei Settori Concorsuali e dei Settori Scientifico-Disciplinari delle Università Italiane della rete OntoPia viene utilizzato per specificare le discipline accademiche. Si raccomanda di utilizzare concetti a livello di Macrosettore, soprattutto per i progetti interdisciplinari, a meno che non siano disponibili informazioni sufficienti per identificare il settore scientifico disciplinare pertinente.
- Geonames è utilizzato per specificare luoghi geografici.
- Wikidata è usato per specificare luoghi geografici, periodi temporali e persone (livello di priorità più basso se un altro vocabolario o un record di autorità nell'elenco può specificare le informazioni necessarie).
- VIAF è usato per specificare le persone (ha la precedenza su Wikidata).
- TaDiRAH, la tassonomia delle attività di ricerca digitale nelle scienze umanistiche, è utilizzata per specificare i tipi di attività di ricerca. Si raccomanda di utilizzare i concetti dei primi due livelli della tassonomia, a meno che un concetto più specifico non sia più accurato (ad esempio encoding) e di limitarsi a tre, per evitare un uso eccessivo. TaDiRAH può essere utilizzato per specificare sia le attività specifiche coinvolte in un progetto di ricerca, ad esempio il fatto che i collaboratori abbiano programmato qualcosa, sia le attività disponibili agli utenti finali attraverso i servizi di dati, come ad esempio la possibilità di manipolare i dati.
- Le authority tables Data Theme, File Type, Access Right, Language, e Frequency dell'UE sono utilizzate per specificare vari aspetti tecnici delle classe DCAT.
- Il vocabolario ADMS Status viene utilizzato per specificare lo stato di distribuzione di un dataset.
I Vocabolari Controllati KNOT
Lo sviluppo del KNOT-DM e del Catalogo ha messo in evidenza una serie di questioni da considerare e affrontare per quanto riguarda la classificazione degli scholarly digital objects, la loro documentazione e la loro visibilità all'interno del sistema accademico italiano.
I vocabolari controllati KNOT sono stati sviluppati per rispondere a esigenze specifiche del data model che non erano adeguatamente coperte dai vocabolari esistenti, in particolare la necessità di classificare i tipi di scholarly digital objects documentati dal progetto e la necessità di avere un controllo di autorità per le tecnologie utilizzate in questi oggetti. Ciò ha portato alla creazione rispettivamente della Tassonomia KNOT e del Thesaurus tecnologico KNOT, due vocabolari controllati basati su SKOS che fanno parte del KNOT-DM.
Entrambi i vocabolari sono stati sviluppati in un processo iterativo per perfezionare le loro strutture gerarchiche e la loro portata. Introduction to Controlled Vocabularies: Terminology for Art, Architecture, and Other Cultural Works pubblicato dal Getty Research Institute è stato utilizzato come riferimento chiave per aiutare a definire quali tipi di vocabolari utilizzare, mentre lo standard SKOS del W3C è stato scelto per rappresentare questi vocabolari in RDF e "consentirne l'interoperabilità e la connessione al più ampio Web semantico" [1]. Sono stati utilizzati come riferimento anche vocabolari esistenti specifici per il campo delle Digital Humanities, tra cui TaDiRAH, PARTHENOS Vocabularies e la DHA Taxonomy, con questi ultimi due originariamente considerati come soluzioni alle esigenze del progetto KNOT, ma alla fine si sono rivelati carenti in alcune aree chiave.
La tassonomia è stata scelta come tipo di vocabolario controllato per rispondere alle esigenze di una "classificazione ordinata" degli scholarly digital objects al centro del progetto, con una struttura gerarchica semplice attraverso la quale organizzare i diversi tipi e dettagliare le loro relazioni [2]. Il thesaurus, invece, è stato scelto per documentare le tecnologie utilizzate nei progetti di ricerca e scholarly digital objects, in quanto è un tipo di vocabolario controllato più complesso che riflette una "rete semantica di concetti unici" con una molteplicità di relazioni e i necessari controlli "raccomandati per l'uso come autorità nei database relativi all'arte e al patrimonio culturale" [2].

La figura 2 illustra in dettaglio le strutture SKOS utilizzate per entrambi i vocabolari. La tassonomia impiega solo skos:ConceptScheme e skos:Concept, in linea con la sua struttura gerarchica più semplice, mentre il thesaurus fa uso anche di skos:Collection per consentire una struttura più profonda. skos:related è utilizzata per creare connessioni semantiche non gerarchiche tra i concetti all'interno dello stesso vocabolario, mentre skos:closeMatch e skos:relatedMatch sono utilizzate per collegare i concetti ad altri in vocabolari esterni, principalmente il Getty Art & Architecture Thesaurus, la Library of Congress Subject Headings, la tassonomia DHA e i vocabolari PARTHENOS.
Sia il thesaurus che la tassonomia sono intesi come "strumenti vivi e in crescita" [2] che saranno aggiornati per tutta la durata del progetto KNOT. Durante il loro sviluppo è stata creata una linea guida editoriali (vedi sotto). Questa linea guida sono il primo punto di riferimento per qualsiasi aggiornamento dei due vocabolari.
I vocabolari KNOT sono disponibili direttamente dal nostro GitHub sia in formato SKOS che con informazioni aggiuntive formattate con DCAT, analogamente ai vocabolari SKOS disponibili da Schema, il catalogo nazionale della semantica dei dati. È inoltre possibile sfogliarli e accedervi tramite il repository /DH.ARC Vocabularies (e interrogarli tramite API), rendendoli completamente FAIR.
Tassonomia KNOT
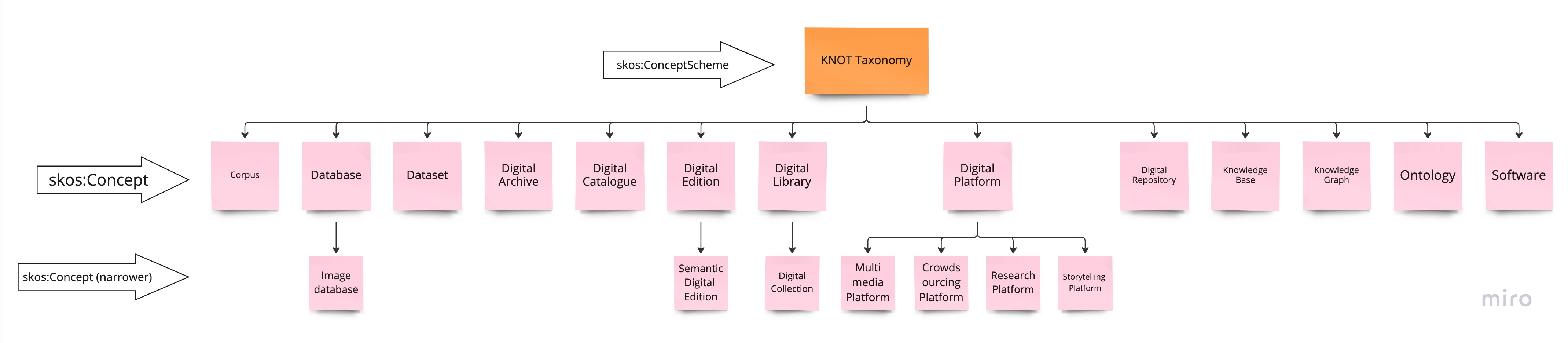
L'elenco dei concetti inclusi nella Tassonomia KNOT riflette i tipi più comuni di digital scholarly object incontrati durante la fase di design di KNOT-DM, sulla base di un censimento dei progetti di ricerca degli Atenei italiani principalmente incentrato sulle discipline umanistiche.
Questa tassonomia non vuole essere un quadro completo o accurato del panorama dei scholarly digital object prodotti da ricerca in italia, ma piuttosto un punto di partenza da cui iniziare ad affrontare questo tema complesso, con l'obiettivo di incorporare gli insegnamenti nelle linee guida che il progetto KNOT produrrà. Mentre ci sono stati sforzi all'interno della comunità internazionale delle Digital Humanities per creare tassonomie utili dei metodi, degli strumenti e delle attività di ricerca, in particolare il DiRT Directory of digital research tools [3] e TaDiRAH, meno attenzione sembra essere stata data agli oggetti che tali metodi, strumenti e attività potrebbero produrre. Ciò rende la classificazione degli scholarly digital objects una linea di indagine particolarmente interessante e utile per il progetto.
I concetti per la tassonomia sono stati scelti e definiti sulla base della letteratura esistente e delle definizioni istituzionali, nonché del punto di vista dei progetti di ricerca stessi, al fine di tenere conto sia dell'uso pratico che di quello ideale. Quindi, un concetto come quello di Database riflette sia la sua definizione tecnica sia il suo utilizzo da parte di molti progetti di ricerca per descrivere una collezione di risorse e i loro metadati, mentre un concetto come quello di Archivio Digitale è in pratica quasi sempre utilizzato per riflettere una collezione di elementi provenienti da diverse entità e unificati tematicamente, in contrasto con la definizione tradizionale di una collezione di documenti provenienti da una persona o da un'organizzazione e creati nel corso della loro attività.
Con il progredire del progetto KNOT, l'intenzione è di perfezionare ulteriormente la tassonomia per includere altri concetti rilevanti e trovare il modo di conciliare gli usi pratici e ideali.
La Figura 3 illustra in dettaglio la struttura e i concetti della tassonomia KNOT nella sua prima versione. La versione attuale può essere facilmente sfogliata e consultata su il /DH.ARC Vocabularies repository.
Thesaurus tecnologico KNOT
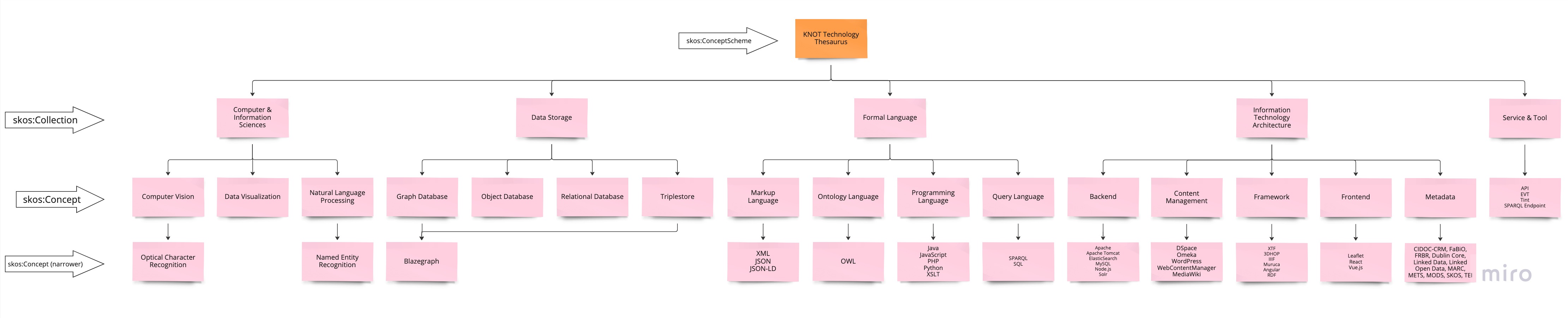
I concetti per il Thesaurus tecnologico KNOT sono stati raccolti dal stesso censimento usato per la tassanomia, con particolare attenzione ai concetti relativi allo stack tecnologico di applicazioni web. Sfortunatamente, i thesauri esistenti spesso mancano di concetti relativi a questo particolare punto di interesse. I concetti sono stati poi ulteriormente ampliati per includere anche attività di ricerca, servizi e strumenti e per far sì che il thesaurus fosse un punto di riferimento più completo per i vari aspetti tecnologici degli digital scholarly objects.
Da qui la decisione di utilizzare skos:Collection per creare una gerarchia più profonda e raggruppare i concetti che hanno qualcosa in comune, decidendo di iniziare con cinque collezioni: Scienze Informatiche (che rappresenta i compiti e le tecniche di ricerca), Data Storage (Memorizzazione di Informazioni), Linguaggi Formali (che rappresenta i linguaggi di programmazione e altri linguaggi tecnologici), Infrastruttura Informatica (che rappresenta lo stack IT), e Servizi & Strumenti (che rappresenta gli elementi che i progetti di ricerca creano o rendono disponibili). Come nel caso della tassonomia, queste raccolte non hanno la pretesa di essere perfette o esatte, ma riflettono piuttosto le esigenze del progetto nel suo primo anno di vita e fungono da punto di partenza per riflettere sulle questioni specifiche della descrizione dettagliata delle tecnologie che aiutano a fare degli scholarly digital objects esempi di patrimonio culturale digitale.
A differenza della tassonomia, le definizioni dei concetti nel thesaurus sono state mantenute il più possibile semplici e fattuali e, laddove possibile, sono state prese da fonti affidabili come la serie Springer Handbook o da vocabolari esistenti come il Getty AAT e il LoC Subject Headings.
La Figura 4 illustra in dettaglio la struttura e i concetti del thesaurus nella sua prima versione. La versione attuale può essere facilmente sfogliata e consultata su il /DH.ARC Vocabularies repository.
Linee guida editoriali dei vocabolari controllati KNOT
Le linee guida editoriali sono intese come il primo punto di riferimento per l'aggiornamento dei vocabolari KNOT. Gli aggiornamenti dei vocabolari possono essere suggeriti da chiunque, ma possono essere implementati solo da un membro del team di progetto KNOT.
- I campi obbligatori per un nuovo concetto sono:
skos:prefLabeleskos:altLabel,skos:definition,dcterms:source, eskos:closeMatchoskos:relatedMatch. Proprietà strutturali, comeskos:narrower,skos:broader, eskos:relateddevono essere inclusi in base alla posizione del concetto nella gerarchia. - Il posizionamento di un nuovo concetto deve essere considerato innanzitutto all'interno della gerarchia esistente, usando
skos:narroweroskos:topConceptOf. Solo se nessunaskos:Collectionesistente è sufficiente per accogliere il concetto, si deve prendere in considerazione la creazione di una nuova collezione. skos:prefLabeldeve sempre privilegiare il termine più comunemente usato per il concetto che non sia un'abbreviazione.skos:altLabeldevono sempre includere abbreviazioni e altri termini che possono essere più comuni nei settori in cui il termine è utilizzato (gergo).- Non ripetere gli elementi condivisi dei concetti nella loro definizione, ma includerli nella definizione del
skos:ConceptScheme. Questo vale soprattutto per le idee che i concetti della tassonomia hanno in comune, come l'uso di oggetti digital born e/o digitalizzati o il fatto che la domanda del progetto di ricerca sia un tema comune per la selezione dei dati. - Un servizio deve essere riutilizzabile e accessibile.
skos:definitioncan differ from accepted definitions of the concept to reflect the point of view of the project but should do so based on evidence. Definitions should also where possible make clear what affordances the concept offers users.skos:definitionpuò differire da quella accettata per riflettere il punto di vista del progetto, ma deve essere basata su esempi. Le definizioni dovrebbero anche chiarire, ove possibile, quali sono le affordance che il concetto offre agli utenti.- Tipi di affordance: produzione e/o estrazione di conoscenza, ricerca/trovabilità, collaborazione/partecipazione, interattività, analisi, multimodalità, intertestualità.
- Nel thesaurus i concetti sono descritti nel modo più semplice possibile, facendo riferimento al tipo di tecnologia (ad esempio, software), agli aggettivi pertinenti (ad esempio, open source), alla tecnologia utilizzata (ad esempio, linguaggi di programmazione) e a casi d'uso noti (ad esempio, uno stack LAMP).
skos:relatedpuò essere usata per creare collegamenti interni rilevanti, come ad esempio tra un software e il linguaggio di programmazione usato per crearlo. - In the taxonomy
skos:relatedis used to create internal links between concepts that could also be understood asskos:narrowerin the real world. This is because it is preferred for concepts in the taxonomy to beskos:topConceptOfunless it is absolutely clear that it is a more specific version of an existing concept. For example, a Semantic Digital Edition is a narrower type of Digital Edition but a Knowledge Base is related to a Database, rather than being in a hierarchical relationship with it. - Nella tassonomia
skos:relatedè usato per creare collegamenti interni tra concetti che potrebbero anche essere intesi comeskos:narrower. Questo perché è stato scelto che i concetti della tassonomia sianoskos:topConceptOf, a meno che non sia assolutamente chiaro che si tratta di una versione più specifica di un concetto esistente. Basato su questo, le Edizioni digitali semantiche sono concetto “narrower” di Edizione digitale ma una Knowledge Base è un concetto “related” di un Database. - The
skos:closeMatchproperty is used when an external vocabulary includes a near-identical concept (based on both the title of the concept and its definition, for example an existing concept for Javascript), whileskos:relatedMatchis used for related concepts (for example the concept of Semantic Web is related to the concept of Linked Data). skos:closeMatchsi usa quando un vocabolario esterno include un concetto quasi identico (in base sia al titolo del concetto che alla sua definizione), mentreskos:relatedMatchsi usa per i concetti correlati (per esempio, il concetto di Semantic Web è correlato al concetto di Linked Data).- I termini sono al singolare.
- L'inglese e l'italiano sono le lingue principali per entrambi i vocabolari.
References
[1] “SKOS Simple Knowledge Organization System Reference.” n.d. Www.w3.org. Accessed July 11, 2023. https://www.w3.org/TR/skos-reference/.[2] Harping, Patricia. 2010. Introduction to Controlled Vocabularies: Terminology for Art, Architecture and Other Cultural Works. Santa Monica, CA: Getty Research Institute.
[3] Perkins, Jody, Quinn Dombrowski, Luise Borek, and Christof Schöch. “Project Report: Building Bridges to the Future of a Distributed Network: From DiRT Categories to TaDiRAH, a Methods Taxonomy for Digital Humanities.” In Proceedings of the 2014 International Conference on Dublin Core and Metadata Applications, 181–83. DCMI’14. Austin, Texas: Dublin Core Metadata Initiative, 2014.
Struttura
Scopri di più sui diversi segmenti che compongono il KNOT-DM.
Moduli
Scopri di più su come utilizzare i diversi moduli di KNOT-DM.